概要
内部テーブルは複数行複数列の仕切りを持った箱となります。
Excelをイメージして頂くと分かりやすいかと思います。
プログラム内で取得したデータを一時的に保持する場合に用いる事が多く、一時的に保持したデータを修正/追加/読込み/取出し/検索条件/出力と様々な形で使用されます。
一時的とはプログラムが実行されて終了するまでの間となり、作業メモリに保持されます。
長期的に保持する場合はABAPディクショナリ(SE11)より作成されたテーブルを使用して保持する必要があります。
一時的に保持した値を取出したり修正後に格納したりする際は構造(ワークエリア/作業領域)を使用してデータの受渡しを行います。(図を参照)
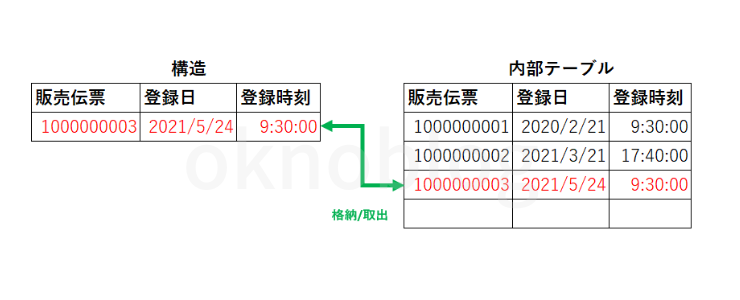
内部テーブルは主に3種類存在し、「標準テーブル」「ソートテーブル」「ハッシュテーブル」があります。(他にはANYテーブル、INDEXテーブルが存在します。)
標準テーブルを基本的に使用していれば間違えは無いのですがパフォーマンス等影響してくるので詳しくは別記事で解説します。(準備中)
命令文
内部テーブルの定義の仕方を3つ紹介します。定義の仕方が異なるだけで内部テーブルを作るという目的は同じになります。
命令文1と命令文2が良く使用される命令文となります。
どちらを使用した方が良いかはプロジェクト毎で異なり、規約や既存のアドオンプログラムなどから判断します。
命令文3はおすすめしないやり方で構造(ワークエリア/作業領域)を直接定義したものを参照して内部テーブルを作成しています。おすすめしない理由は再利用できないのでメンテナンス性に欠けるためです。
TYPES:
BEGIN OF 構造化データ型,
項目 TYPE データ型,
項目 TYPE データ型,
…
END OF 構造化データ型,
内部テーブル型 TYPE STANDARD TABLE OF 構造化データ型.
DATA:
構造(作業領域またはワークエリア) TYPE 構造化データ型,
内部テーブル TYPE 内部テーブル型.
DATA:
BEGIN OF 構造(作業領域またはワークエリア),
項目 TYPE データ型,
項目 TYPE データ型,
…
END OF 構造(作業領域またはワークエリア).
DATA:
内部テーブル LIKE STANDARD TABLE OF 構造(作業領域またはワークエリア).
特徴
特徴は以下の通りです。内部テーブルを編集する際は1行ずつ行われます。
基本的に同じ型で1行格納できる構造(ワークエリア/作業領域)を用いて1行ずつ編集するため構造(ワークエリア/作業領域)と内部テーブルはセットで定義する事が多いです。
内部テーブルの種類については主に3種類で詳しくは概要で紹介した記事をご確認ください。(準備中)
- 複数行複数列の仕切りを持つ箱である
- 構造(ワークエリア/作業領域)を使用して内部テーブルを編集する
- 構造(作業領域またはワークエリア)とセットで内部テーブルも定義する
- 内部テーブルは「標準テーブル」「ソートテーブル」「ハッシュテーブル」の3種類ある
(他にはANYテーブル、INDEXテーブルが存在します。)
コーディング
命令文1、命令文2、命令文3をSAMPLE1、SAMPLE2、SAMPLE3として定義して値の格納と出力を行っています。仕組みを理解する事を重視したため簡素な内容にしています。
APPEND命令の内部テーブルを全てSAMPLE1のものにする事でSAMPLE1の内部テーブルに複数行格納されることを確認することができますので試してみてください。
*-----------------------------------------------------------------------*
* 型定義
*-----------------------------------------------------------------------*
TYPES:
BEGIN OF TA_SAMPLE1,
BANKS TYPE BANKS, "銀行国コード
BANKL TYPE BANKL, "銀行コード
BANKA TYPE BANKA, "銀行名
END OF TA_SAMPLE1,
BEGIN OF TA_SAMPLE2,
BANKS TYPE BANKS, "銀行国コード
BANKL TYPE BANKL, "銀行コード
BANKA TYPE BANKA, "銀行名
END OF TA_SAMPLE2,
TA_TABLESAMPLE2 TYPE STANDARD TABLE OF TA_SAMPLE2.
*-----------------------------------------------------------------------*
* 構造(ワークエリア/作業領域)定義
*-----------------------------------------------------------------------*
DATA:
WA_SAMPLE1 TYPE TA_SAMPLE1,
WA_SAMPLE2 TYPE TA_SAMPLE2.
DATA:
BEGIN OF WA_SAMPLE3,
BANKS TYPE BANKS, "銀行国コード
BANKL TYPE BANKL, "銀行コード
BANKA TYPE BANKA, "銀行名
END OF WA_SAMPLE3.
*出力用
DATA:
WA_OUTPUT1 LIKE WA_SAMPLE1,
WA_OUTPUT2 LIKE WA_SAMPLE2,
WA_OUTPUT3 LIKE WA_SAMPLE3.
*-----------------------------------------------------------------------*
* 内部テーブル定義
*-----------------------------------------------------------------------*
DATA:
IT_SAMPLE1 TYPE STANDARD TABLE OF TA_SAMPLE1,
IT_SAMPLE2 TYPE TA_TABLESAMPLE2,
IT_SAMPLE3 LIKE STANDARD TABLE OF WA_SAMPLE3.
*************************************************************************
*START-OF-SELECTION.
*************************************************************************
WA_SAMPLE1-BANKS = 'JP'.
WA_SAMPLE1-BANKL = '0711111'.
WA_SAMPLE1-BANKA = '銀行名1'.
APPEND WA_SAMPLE1 TO IT_SAMPLE1.
WA_SAMPLE2-BANKS = 'US'.
WA_SAMPLE2-BANKL = '0822222'.
WA_SAMPLE2-BANKA = '銀行名2'.
APPEND WA_SAMPLE2 TO IT_SAMPLE2.
WA_SAMPLE3-BANKS = 'DE'.
WA_SAMPLE3-BANKL = '0933333'.
WA_SAMPLE3-BANKA = '銀行名3'.
APPEND WA_SAMPLE3 TO IT_SAMPLE3.
*************************************************************************
*END-OF-SELECTION.
*************************************************************************
WRITE:
/'SAMNPLE1',
/'WA_SAMPLE1-BANKS' ,'WA_SAMPLE1-BANKL' ,'WA_SAMPLE1-BANKA'.
LOOP AT IT_SAMPLE1 INTO WA_OUTPUT1.
WRITE:
/ WA_OUTPUT1-BANKS ,18 WA_OUTPUT1-BANKL ,35 WA_OUTPUT1-BANKA.
ENDLOOP.
SKIP.
WRITE:
/'SAMNPLE2',
/'WA_SAMPLE2-BANKS' ,'WA_SAMPLE2-BANKL' ,'WA_SAMPLE2-BANKA'.
LOOP AT IT_SAMPLE2 INTO WA_OUTPUT2.
WRITE:
/ WA_OUTPUT2-BANKS ,18 WA_OUTPUT2-BANKL ,35 WA_OUTPUT2-BANKA.
ENDLOOP.
SKIP.
WRITE:
/'SAMNPLE3',
/'WA_SAMPLE3-BANKS' ,'WA_SAMPLE3-BANKL' ,'WA_SAMPLE3-BANKA'.
LOOP AT IT_SAMPLE3 INTO WA_OUTPUT3.
WRITE:
/ WA_OUTPUT3-BANKS ,18 WA_OUTPUT3-BANKL ,35 WA_OUTPUT3-BANKA.
ENDLOOP.
SKIP.
以下実行結果













TYPES:
BEGIN OF 構造化データ型,
項目 TYPE データ型,
項目 TYPE データ型,
…
END OF 構造化データ型.
DATA:
構造(作業領域またはワークエリア) TYPE 構造化データ型,
内部テーブル TYPE STANDARD TABLE OF 構造化データ型.